Use mutation testing to replace code coverage
It is pretty common to use some sort of code coverage measurement tool along with unit tests to gather feedback on completeness of your test suite. Measuring code coverage is great start to find out if your code needs more testing. But by it’s nature it also comes with some caveats. In this article I’ll explain these caveats and how mutation testing fills these caps and turns out more valuable as a source of feedback.
A limitation of code coverage
Code coverage measurement works pretty straight forward. When a test runs a records is kep on which lines and statements were hit during that test execution. That mechanism might leave some unnoticeable gaps though.
Let’s take the following Person class. It has a single method to determine if the person is an adult or not.
public class Person(int age)
{
public bool IsAdult()
{
if (age >= 18)
{
return true;
}
return false;
}
}
To test that code you could write something like below. One test that results in true and one that results in false. This covers all possible outcomes.
public class PersonTest
{
[Theory]
[InlineData(19, true)]
[InlineData(17, false)]
public void Adultlogic(int age, bool expected)
{
// Arrange
var sut = new Person(age);
// Act
var actual = sut.IsAdult();
// Assert
Assert.Equal(expected, actual);
}
}
Great success! Running this test results in a perfect coverage score of 100%.

So all is good, right? Well mostly….. What about the edge case? In case you did your Boundary-value analysis you would have added that test in the first place. Testing with value 18 is probably something really obvious to the more experienced developer. But what if the logic is more complex? The code coverage measurement was clearly not 100% watertight here.
Lack of assertions
Sometimes reality can be even a bit worse though. When software and the test grows more complex you might even end up with a test case that even lacks the assertion. Or Asserts the wrong thing due to human error. Hard to imagine this happening with this simple code, but I’m sure we have all seen a a test or two that actually did not test anything at all. Just like the following test. Someone messed up the Assert.
public class PersonTest
{
[Theory]
[InlineData(19, true)]
[InlineData(17, false)]
public void Adultlogic(int age, bool expected)
{
// Arrange
var sut = new Person(age);
// Act
var actual = sut.IsAdult();
// Assert
Assert.Equal(actual, actual);
}
}
Again, the measured code coverage is 100%. All code covered!
Mutants to the rescue
Mutation testing can help here. The idea is simple any change to code should make at least one test fail. If it does not it indicates a gap in the testsuite. So we nee mutants, to then kill them….
One popular tool to do this automatically is Stryker. Named after William Stryker from the X-MEN, Known for his extreme intolerance towards mutants.
To run this toll on the above code be sure to install it run:
dotnet tool install -g dotnet-stryker or add it to your tool manifest.
With this example default setting are fine. Which means the tool can be executed with: dotnet stryker from within the unittest project folder.
By default Stryker generates HTML output and gives some basic information on the commandline. Below are the most relevant parts of that output.
Analysis starting.
...
...
Number of tests found: 2 for project /Users/jos/src/MutationAndCoverage/MutationAndCoverage/MutationAndCoverage.csproj. Initial test run started.
7 mutants created
...
2 mutants got status Ignored. Reason: Removed by block already covered filter
2 total mutants are skipped for the above mentioned reasons
5 total mutants will be tested
...
...
Killed: 4
Survived: 1
Timeout: 0
...
...
The final mutation score is 80.00 %
Stryker was able to define 5 that were actually worth to run against the test suite. And so it went ahead and ran the test suite once for every mutant created. Onne of those mutants survived! 4 out of 5 comes down to 80%. In other words, Stryker found a gap in our tests!
The HTML report provides better information. The report displays the code modification (the mutant) that survived the tests. <= could be changed to < without the tests detecting it. This directly points to the gap in our test. The edge case is not checked!
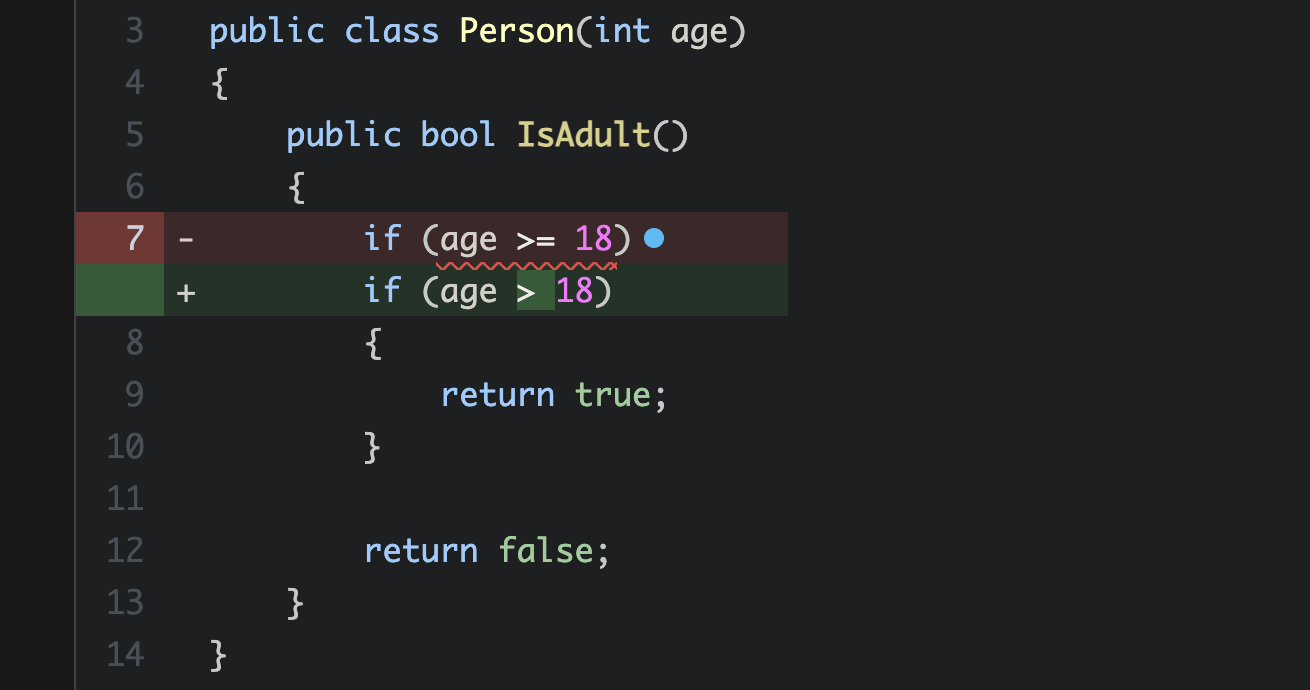
Thanks to mutation testing we now know what code coverage could not tell us. If you would run Stryker on with the tests that have the failing assertion (Assert.Equal(actual, actual);) then the different is even more dramatic. 100% vs 0%.
Conclusion
Mutation testing gives feedback on completeness of the testsuite where code coverage only measures what code had been running during your tests. That is a big difference. The feedback from mutation testing is so much better than just code coverage that I don’t use code coverage anymore.
There is one downside though. It does take more time to calculate all those mutants an to run the whole test suite multiple times. I the next blog I will explain about the smart things Stryker already does for you and what you can do to efficiently use Stryker in your CI/CD pipeline.